That’s it for the 2018 IFComp reviews. My sincere thanks to all the authors; I realize that making an interactive-fiction game is a huge time sink that can often seem unrewarding. The interactive-fiction community is not a particularly friendly place, even if the people in it are, and I wanted to write something here that avoided the dismissiveness and unnecessary unpleasantness I’ve seen in some (certainly not all) other reviews. There’s room here for a huge variety of games, and we need a larger body of reviewers to avoid narrowly focusing attention in what’s already a small, niche community to only those games with the currently trendy intrepreters, styles, and themes. The only way to do that is to generate more reviews, so here’s my small contribution.
That having been said, what sort of game do I personally like? Here’s a histogram of the overall ratings:
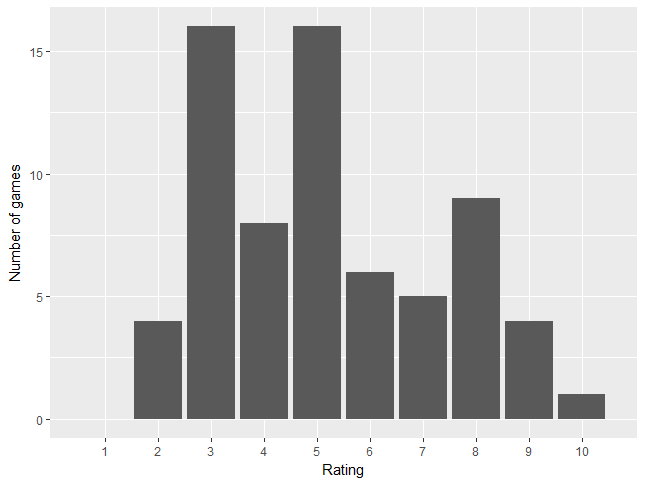
There are only six out of the 76 rated games that I gave a 9 or 10 to. They’re all longer works with prominent puzzles and a light, comedic tone, so that’s a good first approximation to my preferred type of game. For a more detailed look, I’ve marked each game in four categories:
- Parser games rely on parsing text commands, while choice games use a more intuitive but less flexible interface: Choosing a decision among a list of alternatives, dragging actions over keywords in the text to invoke them, etc.
- Standard systems are ones that have been used for a while by a large audience (by IF standards); the most prominent example is Inform. A custom system is one that was developed recently and isn’t commonly used used, or one developed (by the author or someone else) with custom features for one particular game.
- A serious game is a dramatic one that has the goal of affecting the player emotionally. A light one has a less serious tone and is more concerned with the gameplay itself. (Light games are not necessarily comedic; the Zork games fall into that category, for example.)
- A long game more than an hour to complete without a walkthrough; a short game takes less.
(Of course, these labels are somewhat arbitrary and shouldn’t be taken too seriously.) With the large number of games in the competition, we can test whether there are significant differences in my evaluations of the categories above.
- Parser games have a mean score 0.38 higher than that of choice games, corresponding to a p-value of 0.50.
- Standard-system games have a mean score 0.42 higher than that of custom-system games, corresponding to a p-value of 0.44.
- Light games have a mean score 0.61 higher than that of serious games, corresponding to a p-value of 0.25.
- Long games have a mean score 1.42 higher than that of short games, corresponding to a p-value of 0.0023.
(The analysis above uses Welch’s t-test, and the p-values given correspond to the null hypothesis that each pair of populations has the same mean score.) It thus looks like I might have bit of a preference for light parser-based games on standard systems, but I definitely give higher scores to long games than short ones. If you want a high score in my reviews next year, the safest bet is to write a lightly comedic puzzlefest in Inform that takes over an hour to play. Don’t forget to add in a raven or some intense math for a free bonus point.

One thought on “Concluding Remarks”